결국 칼만필터를 하기위해서 공분산까지 뺑돌고있는데... 재미있다.
단지 아직도 아쉬운 건 학교 다닐때, 선형대수나, 통계를 좀 더 했어야했는데.. 하는 아쉬움이...
단지 아직도 아쉬운 건 학교 다닐때, 선형대수나, 통계를 좀 더 했어야했는데.. 하는 아쉬움이...
공분산까지 마무리 지으면서 주성분분석까지 같이 맛만 본다.
영상을 다 보고 작성하는 포스팅인데, 생각보다 어렵진 않다.
너무 겁먹지말자.
공분산의 의미 - 개념잡기 좋다.
https://www.youtube.com/watch?v=yoqIj8Jvj90&t=936s
다시 이전 포스팅의 내용을 가져와서 보면
평균
\(Mean = \frac{자료전체의 합(sum)} {자료의 개수(n)}\)
ex) 데이터가 1,2,3,4,5라면 평균은 ( 1+ 2+ 3+ 4+ 5) / 5 = 3이 됩니다.
분산
\(Variance = \frac{ \Sigma_{i=1}^{n} (x_i - \bar{x})^{2} } { n-1} \)
ex) 분산 = \(\frac{(1-3)^2 + (2-3)^2 + (3-3)^2 + (4-3)^2 + (5-3)^2}{4} = 2.5\)
=> 분산이란 내가 가진 데이터가 평균값을 중심으로 퍼져있는 평균적인 거리
공분산이란?
\(s_{xy} = \frac{1}{n-1}(x_i - \bar{x})(y_i - \bar{y})\)
x의 편차와 y의 편차를 곱한 것의 평균
\(x_i\) = 변수
\(\bar{x}\) = 평균
분산과 공분산 식의 차이를 보자.
분산의 분자 부분은 (변수 - 평균) 제곱이 되는데, 공분산은 다른 변수의 (변수-평균)제곱 이 추가적으로 들어가있다.
분산은 1차적인 거리
공분산은 두 변수의 평균값을 중심으로 퍼져있는 2차원의 방향, 모양에 대한 정보다.

분산은 1차원으로 변수 1개
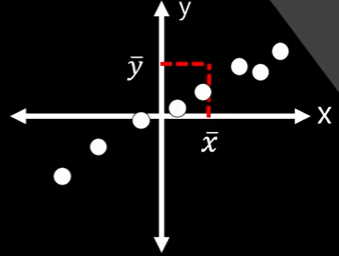
예시데이터
| ID | 국어 | 영어 |
| 1.00 | 95.00 | 95.00 |
| 2.00 | 90.00 | 95.00 |
| 3.00 | 80.00 | 75.00 |
| 4.00 | 60.00 | 70.00 |
| 5.00 | 40.00 | 35.00 |
| 6.00 | 80.00 | 80.00 |
| 7.00 | 95.00 | 90.00 |
| 8.00 | 30.00 | 25.00 |
| 9.00 | 15.00 | 10.00 |
| 10.00 | 60.00 | 70.00 |
| 평균 | 64.50 | 64.50 |
| 분산 | 808.06 | 924.72 |
| 표준편차 | 28.43 | 30.41 |
| 공분산 | 762.25 | |
| 상관계수 | 0.88 |
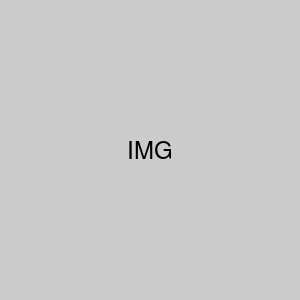
variance covariance matrix로 표현하면
\(C = \begin{bmatrix} 808 & 762 \\ 762 & 925 \end{bmatrix} \)
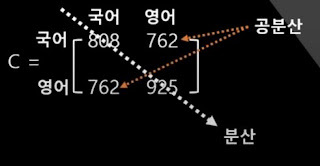
대각성분들은 분산, 반대 대각성분들은 공분산이다.
영어와 영어의 분산은 공분산이고, 국어와 국어의 분산은 공분산이 된다.
공분산은 762으로 양수 이므로 같은 방향으로 퍼져있구나를 짐작케함.
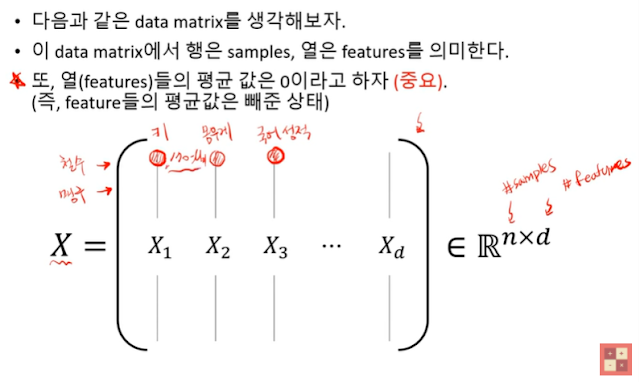
대각행렬은 분산처럼 역할을 하며, 대각행렬이 아닌 부분은 공분산 처럼 된다.
\((X^{T} X)_{ij}\)는 i번째 feature와 j번째 feature의 변동이 닮은 정도를 말해준다.
\(\Sigma = cov(X) = \frac{1}{n}X^TX\)



하. 선형변환을 했을때 크기만 바뀌고 방향을 바뀌지 않는 벡터가 있나요????
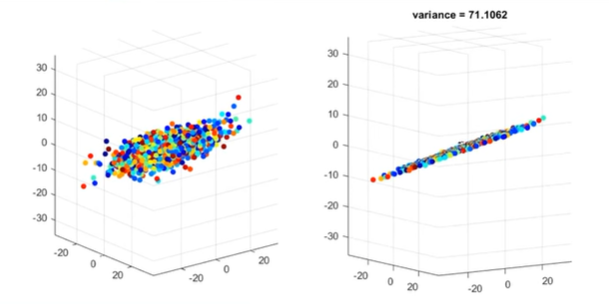
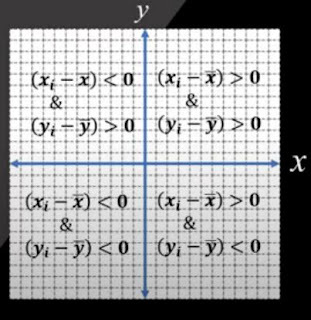
분산은 항상 양수이지만, 공분산은 양수 또는 음수이다.
- 양의 공분산이 나오는 경우
x,y 둘다 같은 부호일 경우
- 음의 공분산이 나오는 경우
x,y가 둘다 다른 부호일 경우
- 공분산이 0일 경우
선형적인 관계가 없다.
아래 그림과 같이... 공분산은 데이터가 가지는 방향에 대한 이야기다.
여러개의 수많은 데이터들을 하나의 variance covariance matrix만으로도
전체 데이터의 분산을 파악할 수 있다는 장점이 있다.
하지만 공분산은 상관관계가 얼마나 큰지는 반영하지 못하기 때문에 상관계수라는 개념이 등장한다.
상관계수 (= 표준화된 공분산)
\(\rho = \frac{cov(x,y)} {\sqrt{var(x)var(y)}} \)
공분산은 측정단위에 영향을 많이 받음. 따라서 표준화가 필요하다.
x,y가 완벽한 선형관계가 가까울 수록 1, -1이 되고, 이 수에 근접할 수록
모이는 정도(power)가 커진다.
조금 더 자세한 버전
공돌이의 수학정리노트 선생님.... 대단하심.
https://www.youtube.com/watch?v=jNwf-JUGWgg&t=194s
https://angeloyeo.github.io/2019/07/27/PCA.html
공분산 행렬의 의미
- 데이터 구조적 의미: 각 feature의 변동이 얼마나 닮았나?
- 수학적 의미: 선형변환(shearing)
- 데이터 구조적 의미: 각 feature의 변동이 얼마나 닮았나?
- 수학적 의미: 선형변환(shearing)
PCA (= projecting data onto eigen vectors of 공분산행렬)
- 공분산 행렬의 Eigen vector & eigen value
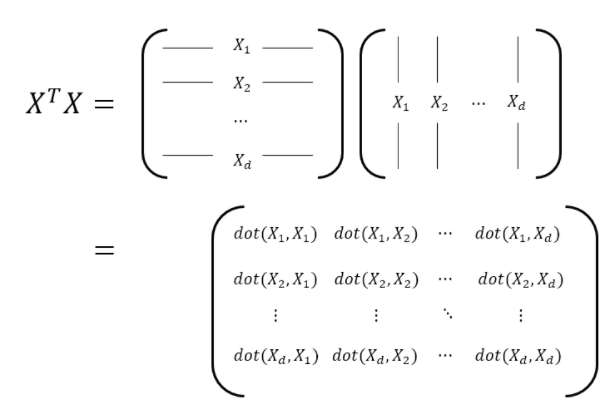
행렬X를 이용해서 공분산행렬을 구해보자. 닮은 정도를 보기위해서는 내적을 해야한다.
대각행렬은 분산처럼 역할을 하며, 대각행렬이 아닌 부분은 공분산 처럼 된다.
dot는 교환법칙이 가능하여... 대칭이된다.
\((X^{T} X)_{ij}\)는 i번째 feature와 j번째 feature의 변동이 닮은 정도를 말해준다.
sample 수(n)이 많아질 수록 그 값이 커진다.
따라서 n을 나준다.
feature들의 평균을 0으로 만들었다는 사실을 잊지말자.
수학정리노트 선생님이 아주 그래프를 잘 만들어주셔서... 이해가 한방에 된다.
PCA = Principal component analysis => 종합성적 계산하기
공분산 행렬의 eigen vector
-PCA 알고리즘은 데이터 구조를 잘 살려주면서 차원감소를 할 수 있게끔하는 방법
- 2차원 평면상의 산점도를 1차원에 정사영시켜 차원을 감소시켜준다고 하면 어떤 벡터에 정사영시키는 것이 가장 좋을까?
= 결국 위에 나온 것처럼... 2차원의 각 변수들의 분산도를 잘 유지하면서 차원축소를 할때 가장 적합한 1차원 선은 무엇일까? 하는 이야기.
과연 (2,1)이 적합한 벡터일까?
정리
- 데이터의 구조를 잘 살려주면서 차원감소하기위해선 정사영 후의 데이터 분포의 분산이 가장 큰 것이 좋다.
- 고로 공분산 행렬을 통해 선형변환할때 주축에 대해서 정사영하는 것이 제일 좋다.
하. 선형변환을 했을때 크기만 바뀌고 방향을 바뀌지 않는 벡터가 있나요????
선형변환을 했을때 크기만 바뀌고 방향을 바뀌지 않는 벡터가 있나요????
선형변환을 했을때 크기만 바뀌고 방향을 바뀌지 않는 벡터가 있나요????
선형변환을 했을때 크기만 바뀌고 방향을 바뀌지 않는 벡터가 있나요????
이해가 딱 되네. eigen vector에 정사영해야한다.
3차원 -> 3개의 eigen vector
eigen value가 큰 2개의 eigen vector가 이루는 평면에 데이터를 정사영하여 2차원으로 차원 감소된 데이터를 획득한다.
반응형
'Study > 칼만필터' 카테고리의 다른 글
| [칼만필터] Chap 14. 파티클필터 (0) | 2022.01.15 |
|---|---|
| [칼만필터] Chap 13. 무향칼만필터 (0) | 2022.01.15 |
| [통계] 평균과 표준편차 (0) | 2022.01.15 |
| [칼만필터] Chap 12. 확장칼만필터 (0) | 2022.01.15 |
| [칼만필터] Chap 11. 기울기 자세 측정하기 (0) | 2022.01.15 |