Chap 13. 무향칼만필터
앞서 통계에 대한 공부를 했다.
문제는 이후에 일어나는 내용들이 확률분포와 관련된 내용들이기 때문이다.
무향칼만필터부터 적용되는 내용들이 사실 많이 이해되지는 않았다.
하지만 일단 책의 내용만 정리해놓고, 차후에 추가적으로 더 이해되도록 정리할 예정이다.
UKF(Unscented Kalman Filter)
13.1 UKF 기본 전략
UKF(Unscented Kalman Filter)는 EKF와 다르게 선형화 과정이 생략된다.
EKF는 오차공분산 예측에 선형화 모델을 사용하였다. 비선형시스템에서는 해석적으로 구하지 못하는 문제를 선형화를 통한 근사화로 해결하였다. 하지만 EKF는 결국 선형화 모델의 정확도가 관건이다. 모델이 정확해야 필터가 제대로 작동한다는 뜻이 된다.
앞서 EKF에서는 오차공분산의 예측값(\(\bar{P}_{k}\) 을 해석적으로 구할 수 없어서 시스템 모델에 야코비안을 사용하였다. UKF에서는 선형화를 통한 근사화가 아닌 샘플링을 통한 근사화 전략이 사용된다. 모델을 수식이 아닌 시스템의 대표하는 몇 개의 데이터를 사용하여 상태변수와 오차공분산의 예측값을 계산한다.
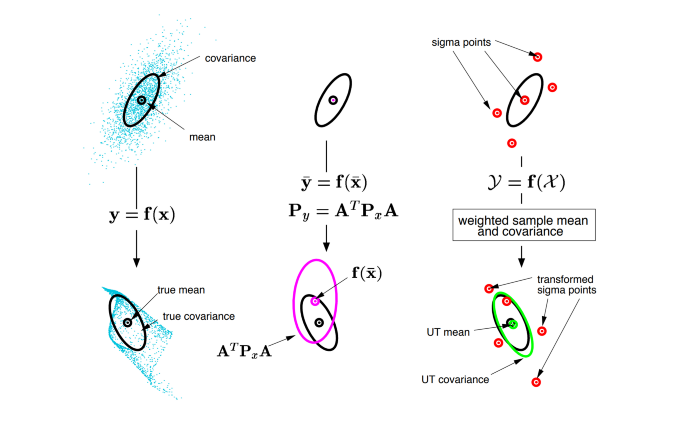
The confidence ellipses and mean values obtained in a process of sampling (reference), EKF and UKF approximations (source: “The Unscented Kalman Filter for Nonlinear Estimation”, Eric A. Wan and Rudolph van der Merwe)
큰 그림은 위와 같다. 다른데서 이미지를 가져왔다.
첫번째 Unscented Transform 무향변환 ( = UT)
직전 시스템의 추정값과 오차공분산을 데이터 몇 개를 시그마포인트 라고 부른다.
현재 시스템에서 추정값과 오차공분산의 예측값은 시그마포인트를 시스템모델로 변환한 데이터로 구할 수 있다.
(추정값, 오차공분산 예측값) = \(f(x)\)
=>변환한 데이터로부터 간접적으로 상태변수, 오차공분산예측값을 간접적으로 구하는 전략
13.2 UKF 알고리즘
기존 칼만필터 알고리즘에서 시스템모델의 예측이 필요한 곳에서 UT가 사용된다.
EKF와 동일한 비선형 모델을 그대로 사용한다.
\(x_{k+1} = f(x_{k}) + w_{k}\)
\(z_{k} = h(x_{k}) + v_{k} \)
계산식이 조금 달라졌을뿐, "예측 -> 칼만이득 계산 -> 추정" 의 반복구조는 그대로이다.

0단계: 초기값 선정
1단계: 시그마 포인트와 가중치 계산
2단계: 추정값과 오차 공분산 예측
현재 시각에서의 상태변수와 오차공분산 예측값 계산.
시스템 모델을 사용하지않고, 시그마 포인트와 UT를 통해 간접 계산함.
3단계: 측정값과 오차공분산 예측
UT를 통해서 측정값의 오차공분산(\(P_{z}\)를 간접적으로 구함.
4단계: 칼만 이득 계산
\(x_k, z_k\)의 공분산행렬(\(P_{xz}\)을 먼저 계산 후 칼만게인을 계산함.
5단계: 추정값 계산
6단계: 오차 공분산 계산
13.3 무향변환(Unscented Transform)
평균이 \(x_m\), 분산이 \(P_x\)인 정규분포를 따르는 상태변수 x
\(x \sim N(x_m, P_x)\)
시그마포인트(\(\chi_{i})\)와 가중치(\(W_i)\)를 정의
\(\chi_{1} = x_m \)
\(\chi_{i+1} = x_m + u_i \) \(i= 1,2, ... ,n\)
\(\chi_{i+n+1} = x_m - u_i \) \(i= 1,2, ... ,n\)
\(W_1 = \frac{\kappa} { n+\kappa} \)
\(W_{i+1} = \frac{1} { 2(n+\kappa)} \) \(i= 1,2, ... ,n\)
\(W_{i+n+1} = \frac{1} { 2(n+\kappa)} \) \(i= 1,2, ... ,n\)
\(U^{T} U = (n+ \kappa) P_x\)
\(u_i\)는 행렬U의 행벡터이고, \(\kappa\)는 임의의 상수이다.
(\(\kappa\)는 (\(n+\kappa)=3\)이 되도록 하는 것이 무난하다.... (이거는 이해가 안된다))
시그마포인트는 상태변수의 확률분포를 대표하는 샘플데이터에 해당된다.
가중치는 평균과 공분산을 계싼할떄 각 시그마포인트의 비중을 결정하는 상수이다.
\(x_m = \displaystyle \sum_{i=1}^{2n+1} W_i \chi_i \)
시그마포인트의 가중평균이 x의 원래 평균값과 같다
\(P_x = \displaystyle \sum_{i=1}^{2n+1} W_i ( \chi_i - x_m)( \chi_i - x_m)^{T} \)
시그마포인트의 가중 공분산은 x의 공분산이 된다.
많은 샘플을 동원하지 않아도, 2n+1개의 시그마포인트와 가중치만 있으면 x의 통계적 특성(평균, 공분산)을 적절하게 표현할 수 있다는 의미
=> 시그마포인트와 가중치는 상태변수의 통계적특성이 대표한다.
n은 차원을 말하는 것 같다. 2차원변수이기 떄문에 시그마포인트는
2 * 2 + 1 = 5개가 된다.
이제는 함수 y= f(x)의 시그마포인트와 가중치를 이용해 평균과 공분산을 구할 수 있다.
\(y_m = \displaystyle \sum_{i=1}^{2n+1} W_i f(\chi_i) \)
\(P_y = \displaystyle \sum_{i=1}^{2n+1} W_i ( f(\chi_i) - y_m)( f(\chi_i) - y_m)^{T} \)
시그라마포인트와 가중치를 f(x)로 변환한 가중평균과 가중공분산을 구하면 y의 평균과 공분산을 근사적으로 얻을 수 있다는 뜻이다.
대표되는 5개의 값을 사용해서 y 의 평균과 공분산이 계산!!

1. x 평균, 공분산 -> \(\chi\) 시그마포인트 선정
2. f(x) 비선형모델로 변환
3. 변환된 f(x) -> 가중 평균, 가중공분산을 계산
UT 함수
\(U^{T} U = (n+ \kappa) P_x\) 를 만족하는 행렬 U를 구하는데 촐레스키 분해(cholesky decomposition)가 사용된다고 한다.
앞서 12장의 모델링은 동일하고, 방법만 UKF로 수행한다.
13.4 예제1 레이다 추적
모델링은 기존과 동일하다.

UKF를 사용하여 얻은 결과


결론
UKF는 비선형 함수 자체를 모사하는 것 보다는 함수의 확률분포를 모사하는 것이 더 낫다는 전략으로 고안된 비선형 칼만 필터이다.
근사화된 선형함수대신 비선형함수의 평균과 공분산을 근사적으로 구하는 것이 더 유리하다는 의도이다. 야코비안을 이용한 선형모델이 불안정하거나 구현하기 어려운 경우에 좋은 대안이 될 수 있다. 야코비안을 해석적으로 쉽게 구할 수 있으면 EKF가 낫고, 구하기 어렵거나 EKF가 발산할 염려가 있다면 UKF를 쓰는 게 더 낫다.UKF가 더 정확한 근사식을 사용한다...
결론은 두개 다 구현해서 비교해보고 사용하는 것이 더 낫다는 저자의 의견이었다.
반응형
'Study > 칼만필터' 카테고리의 다른 글
| [칼만필터] Chap. 15 고주파통과필터(와 저주파필터) (0) | 2022.01.15 |
|---|---|
| [칼만필터] Chap 14. 파티클필터 (0) | 2022.01.15 |
| [통계] 공분산행렬과 PCA(주성분분석) (0) | 2022.01.15 |
| [통계] 평균과 표준편차 (0) | 2022.01.15 |
| [칼만필터] Chap 12. 확장칼만필터 (0) | 2022.01.15 |